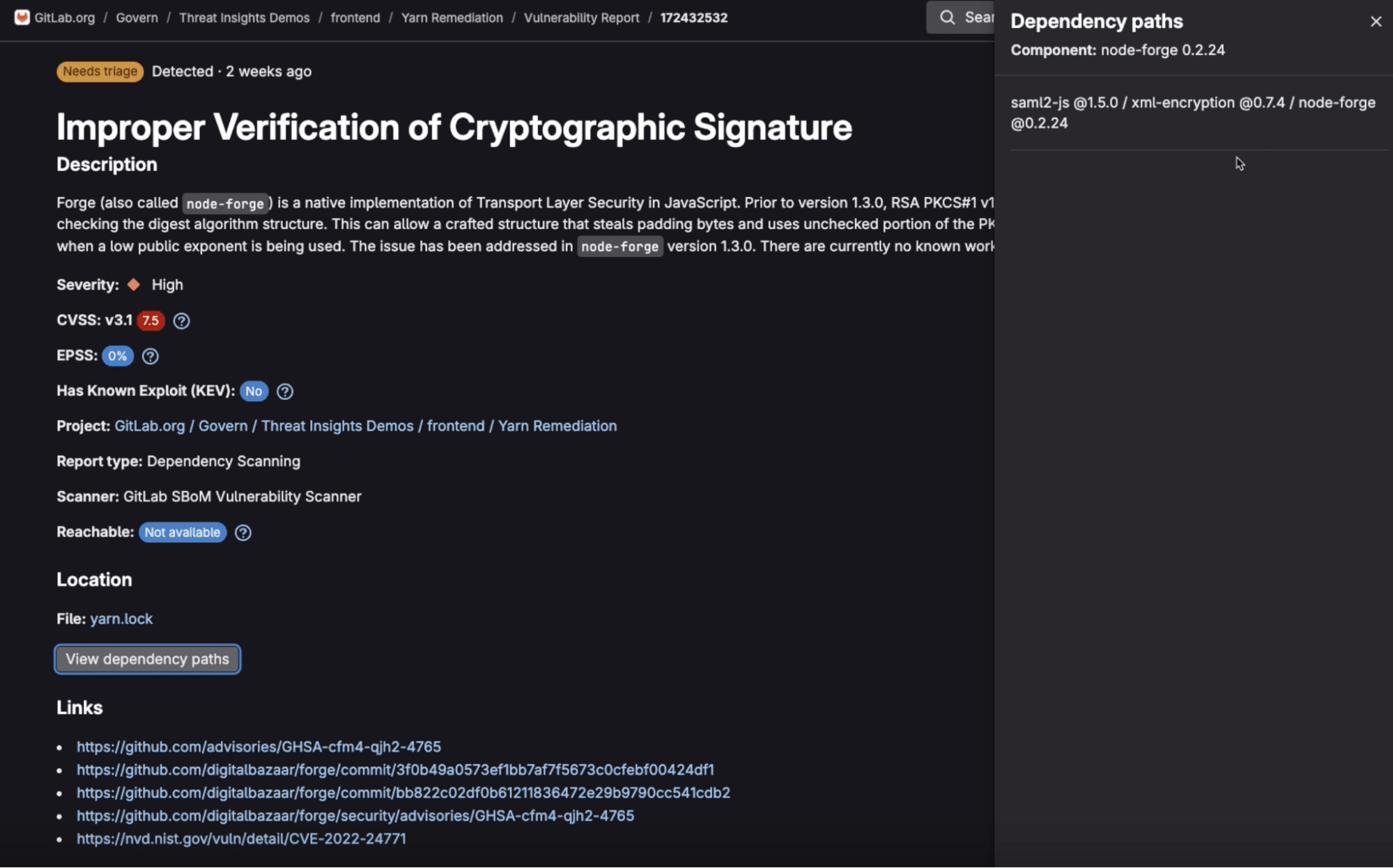
In addition to being available in a variety of IDEs, Agentic Chat is available directly within the GitLab UI for GitLab users with the Duo Pro or Enterprise add-on. Adding Agentic Chat to the GitLab UI helps make this experience more accessible to all GitLab users and easy to integrate into your workflows. To open Agentic Chat:
-
Navigate to any Group or Project in your GitLab instance.
-
Look for the GitLab Duo Chat button (typically in the top right corner).
-
Click to open the chat panel.
-
Toggle to Agentic mode (Beta) in the chat window.
Pro tip: Keep the chat panel open as you work — it maintains context and can help you across different pages and projects.
To get familiar with Agentic Chat, ask about the tools it can work with. This is like using the help command for a command-line tool.
What tools do you have access to?
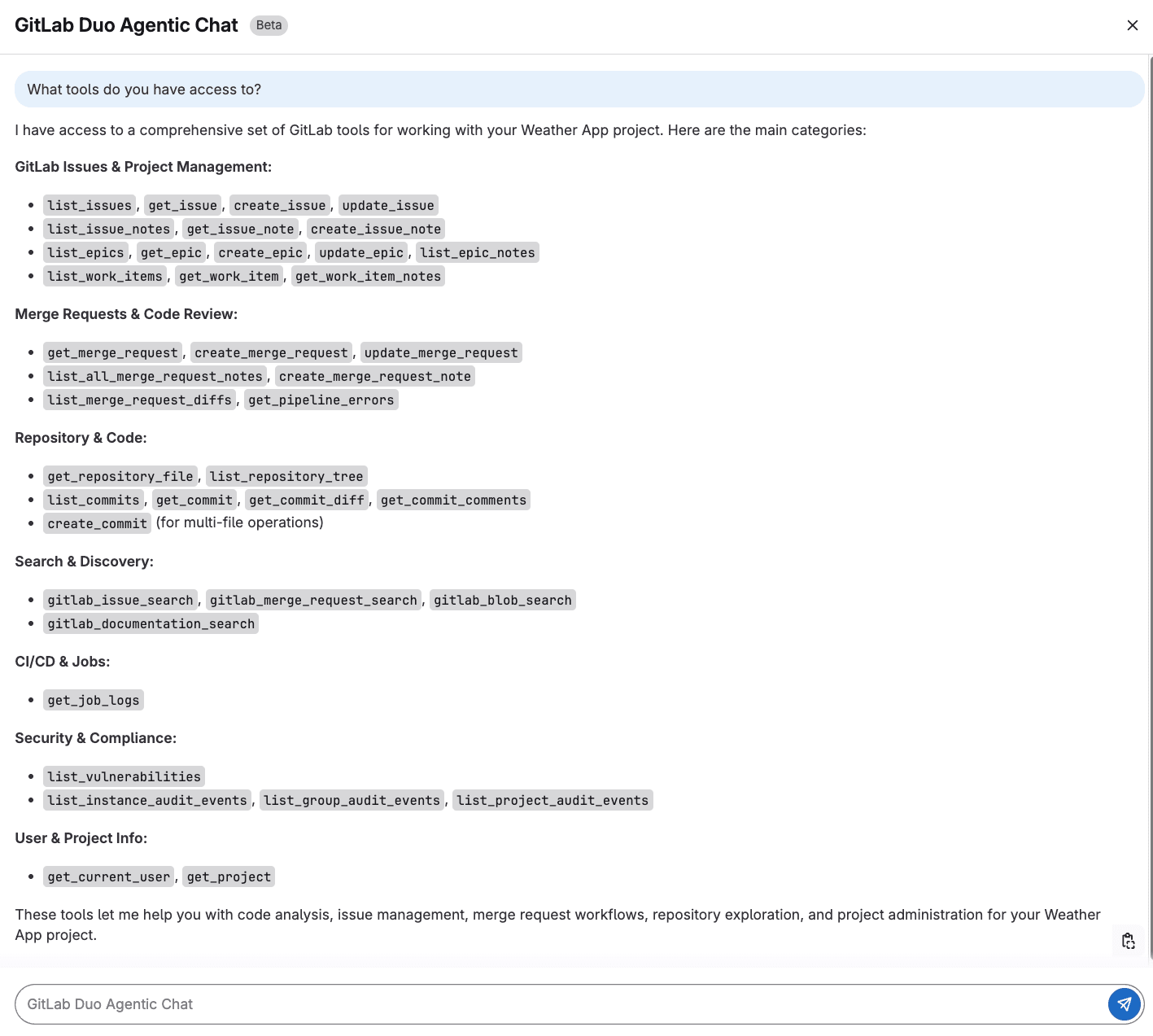
The output above shows us that Agentic Chat has access to a variety of GitLab APIs and data that will allow it to perform complex tasks across the software development lifecycle.
Issue management made easy
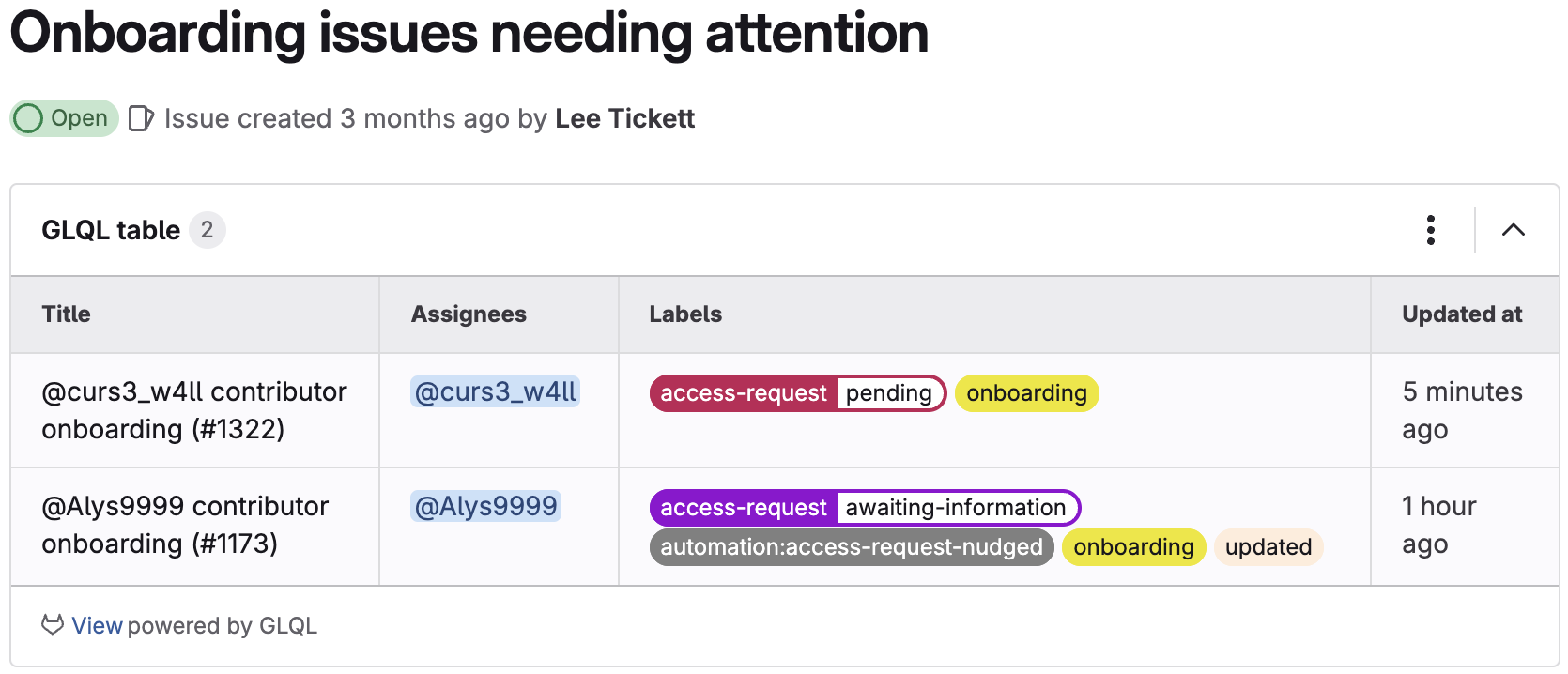
GitLab Duo Agentic Chat can help you keep track of issues, find specific ones, understand the status, and take actions based on conversations in these issues. Instead of navigating through pages and pages of issues, you ask Agentic Chat about the issues in a project. It will respond with high-level information about the issues, including the priority, labels, and the status of the issue.
For a specific issue, Agentic Chat will fetch the issue details, provide a concise summary, highlight recent activity, and share the goal of the issue. This is particularly helpful when you need context or updates before a meeting or are researching the issue before picking it up.
<div style="padding:56.25% 0 0 0;position:relative;"><iframe src="https://player.vimeo.com/video/1107479358?badge=0&autopause=0&player_id=0&app_id=58479" frameborder="0" allow="autoplay; fullscreen; picture-in-picture; clipboard-write; encrypted-media; web-share" referrerpolicy="strict-origin-when-cross-origin" style="position:absolute;top:0;left:0;width:100%;height:100%;" title="Agentic Chat UI Issue Management"></iframe></div><script src="https://player.vimeo.com/api/player.js"></script>
<p></p>
You can also try more complex queries if you're looking to better understand a project overall. And once you've discovered these issues, you can make changes to them like adding labels, updating milestones, and re-organizing them.
For example, maybe you're looking for all the issues that are database- or performance-related in order to prioritize them in the next sprint. You could task Agentic Chat with the following prompt.
Analyze all issues labeled 'performance' and 'database' - group them by component and show me which ones have had the most discussion activity in the last 30 days.
Agentic Chat will respond with issues grouped by the backend and frontend component of a project, identify the issues with significant discussion activity, and provide insights on these kinds of issues (e.g., when were most of these issues created or which component issues have more active discussion).
Create an issue template for bug reports that includes:
- Steps to reproduce
- Expected behavior vs actual behavior
- Environment details (browser, OS, GitLab version)
- Severity assessment
- Screenshots/error logs section
Name it "bug_report.md" and format it as a proper GitLab issue template
CI/CD support
This is where GitLab Duo Agentic Chat truly becomes your debugging superhero. We've all been there: a pipeline fails and you have to click through job logs trying to understand what went wrong. Agentic Chat can do more than just explain the failure to you and suggest recommendations. After reviewing the failed pipeline logs, Agentic Chat can suggest a fix and also add the fix to a merge request you are working on.
Let's say you have a merge request adding a new feature, but the pipeline is failing. Instead of clicking through each failed job and trying to piece together what's wrong, you can ask Agentic Chat to investigate.
Agentic Chat will analyze the pipeline, check the job logs, and explain that the tests are failing because of missing test data or configuration issues. But here's where it gets even more powerful — you don't have to stop at understanding the problem. Agentic Chat can also act on the advice it presents and add commits to fix the pipeline in the merge request.
<div style="padding:56.25% 0 0 0;position:relative;"><iframe src="https://player.vimeo.com/video/1107495269?badge=0&autopause=0&player_id=0&app_id=58479" frameborder="0" allow="autoplay; fullscreen; picture-in-picture; clipboard-write; encrypted-media; web-share" referrerpolicy="strict-origin-when-cross-origin" style="position:absolute;top:0;left:0;width:100%;height:100%;" title="GitLab Agentic Chat CI/CD Fix"></iframe></div><script src="https://player.vimeo.com/api/player.js"></script>
Building complex prompts
GitLab Duo Agentic Chat can also help you craft your prompts. Let's say that you're running a bug bash with your team and want to triage all possible issues that might be bug reports.
If you use a simple prompt like below, Agentic Chat will come up with ways to find the related issues, such as searching for terms or pattern matching:
I need help writing an effective prompt to find all possible bug report issues in my GitLab project, including those that might not be properly labeled as "bug".
Often you can use the recommendations in Agentic Chat to build a more in-depth prompt based on what you're looking for:
I need help writing an effective prompt to find all possible bug report issues in my GitLab project, including those that might not be properly labeled as "bug". Please help me create a prompt that will:
1. Search for common bug-related terminology beyond just the word "bug"
2. Identify patterns that indicate bug reports (like "steps to reproduce", "expected vs actual behavior")
3. Find technical issues that might be bugs (errors, crashes, performance problems)
4. Catch user-reported problems that could be bugs but use different language
The prompt should ensure we don't miss any potential bugs regardless of how they're described or labeled. What would be the most effective approach and search strategy for this?
Once you have the prompt and you're able to search for the issues you're looking for, that's where Agentic Chat really shines. Agentic Chat can triage and update those issues for you to prepare them for the bug bash:
Find and triage all bug-related issues for our bug bash event. Execute these steps:
1. Search for potential bugs using individual searches:
- Core terms: "bug", "fix", "error", "broken", "issue", "problem", "not working"
- Bug patterns: "steps to reproduce", "expected behavior", "regression"
- Technical issues: "exception", "crash", "console error", "500 error", "404 error"
- Performance: "slow", "freezes", "unresponsive"
2. For each issue found:
- Add the "Event - Bug Bash" label
- Assign appropriate bug severity label (critical/high/medium/low)
- Add to the current bug bash milestone
- If missing "bug" label, add it
3. Create a triage list organized by:
- Critical bugs (data loss, crashes, security)
- High priority (blocking features, frequent errors)
- Medium priority (workarounds available)
- Low priority (minor UI issues)
Search both open and closed issues. Focus on actionable bugs that can be fixed during the bug bash, excluding enhancement requests. Provide a summary table with issue numbers, titles, and assigned severity for the bug bash team.
You can ask Agentic Chat to create a bug report template, which increases efficiency and eliminates some manual effort. Also, future bug reports will have the structure and labels you need for more efficient triaging.
Tips for effective prompting
When you're working with GitLab Duo Agentic Chat, it's important to phrase your requests with action-oriented verbs like "create," "update," "fix," or "assign." This will trigger the agentic tools to take action rather than summarize or share information with you. One approach before taking agentic actions can be to request summaries and analyses — the way we did with the issues about bugs. Then, see what gets returned before taking actions like applying a label or adding to a milestone.
It's also important to give clear criteria when asking for bulk operations. Specify exact conditions like "all issues with the 'bug' label created in the last week" or "merge requests waiting for review for more than 3 days." The more specific you are, the more accurate and helpful the results will be.
Since Agentic Chat has the ability to maintain context, you can chain requests and build on previous requests. After getting an initial set of issues, you might ask "From those issues, which ones are unassigned?" and then follow up with "Assign the high-priority ones to the backend team." This allows you to refine and act on information iteratively.
We recommend starting with an open-ended request and allowing GitLab Duo to help you look for patterns or similar problems across your project. That will help you catch any problem that you may have missed or understand the scope of the challenge before taking action.
Get hands-on with GitLab Duo Agentic Chat
We hope all the ideas above give you some thoughts on getting started with Agentic Chat, but we are even more excited to see all our users' ideas come to life with it. To try the Agentic Chat UI experience in your next project, sign up for a free trial of GitLab Ultimate with Duo Enterprise. You can learn more about GitLab Duo Agentic Chat on our documentation page, which also details how to enable Agentic Chat in the GitLab UI.
]]>

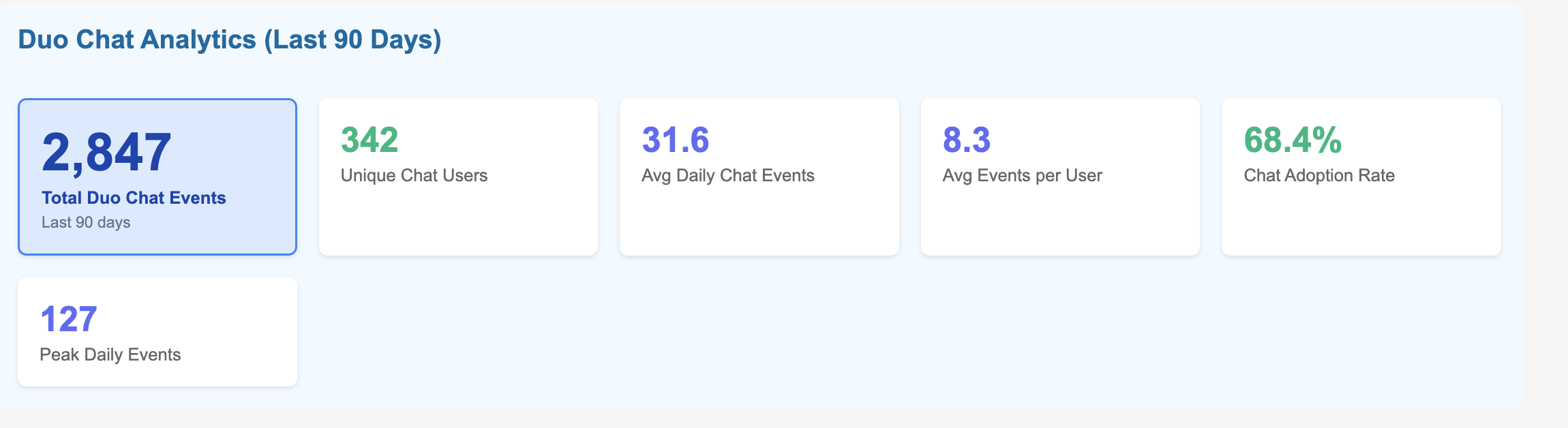
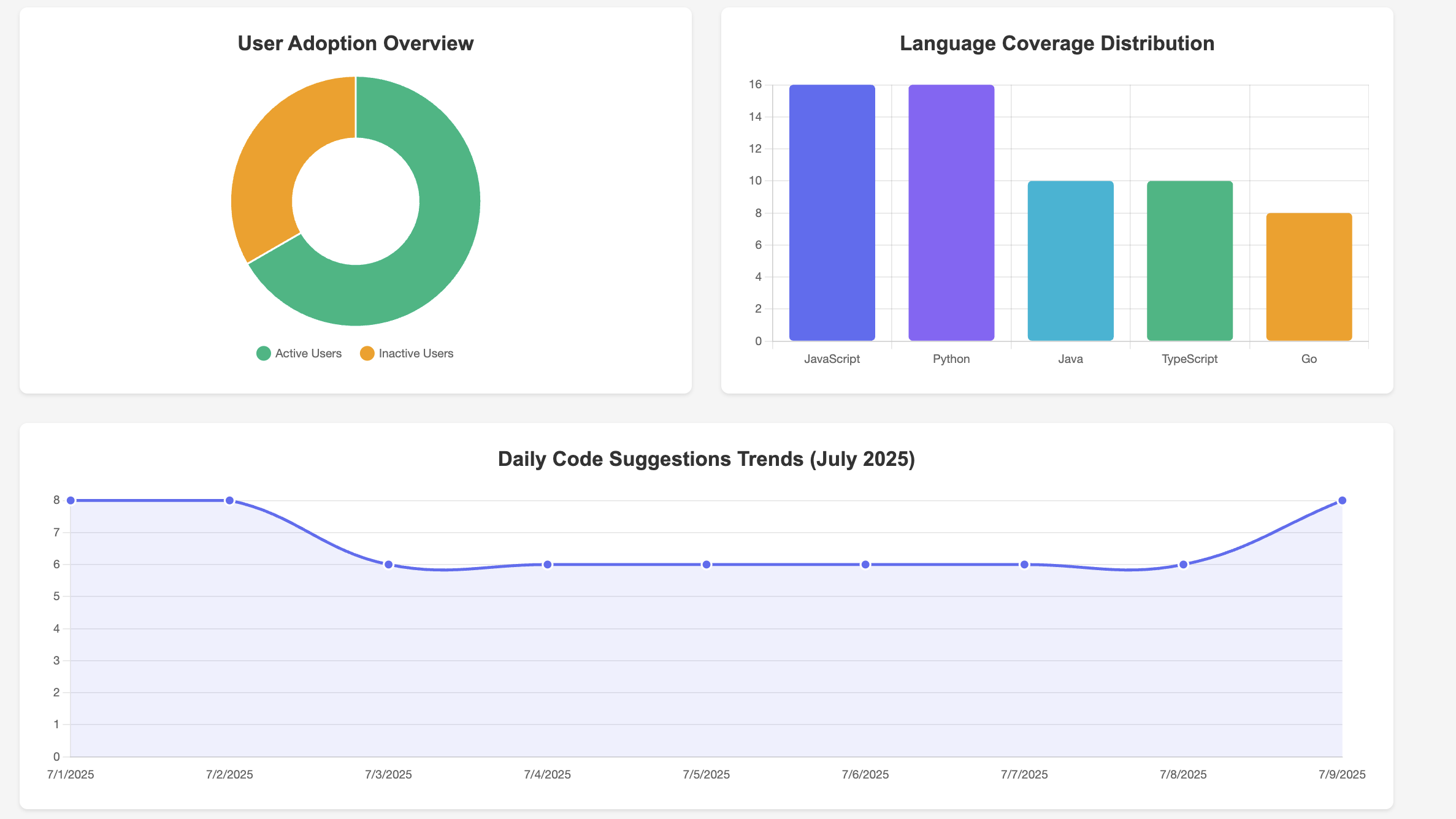
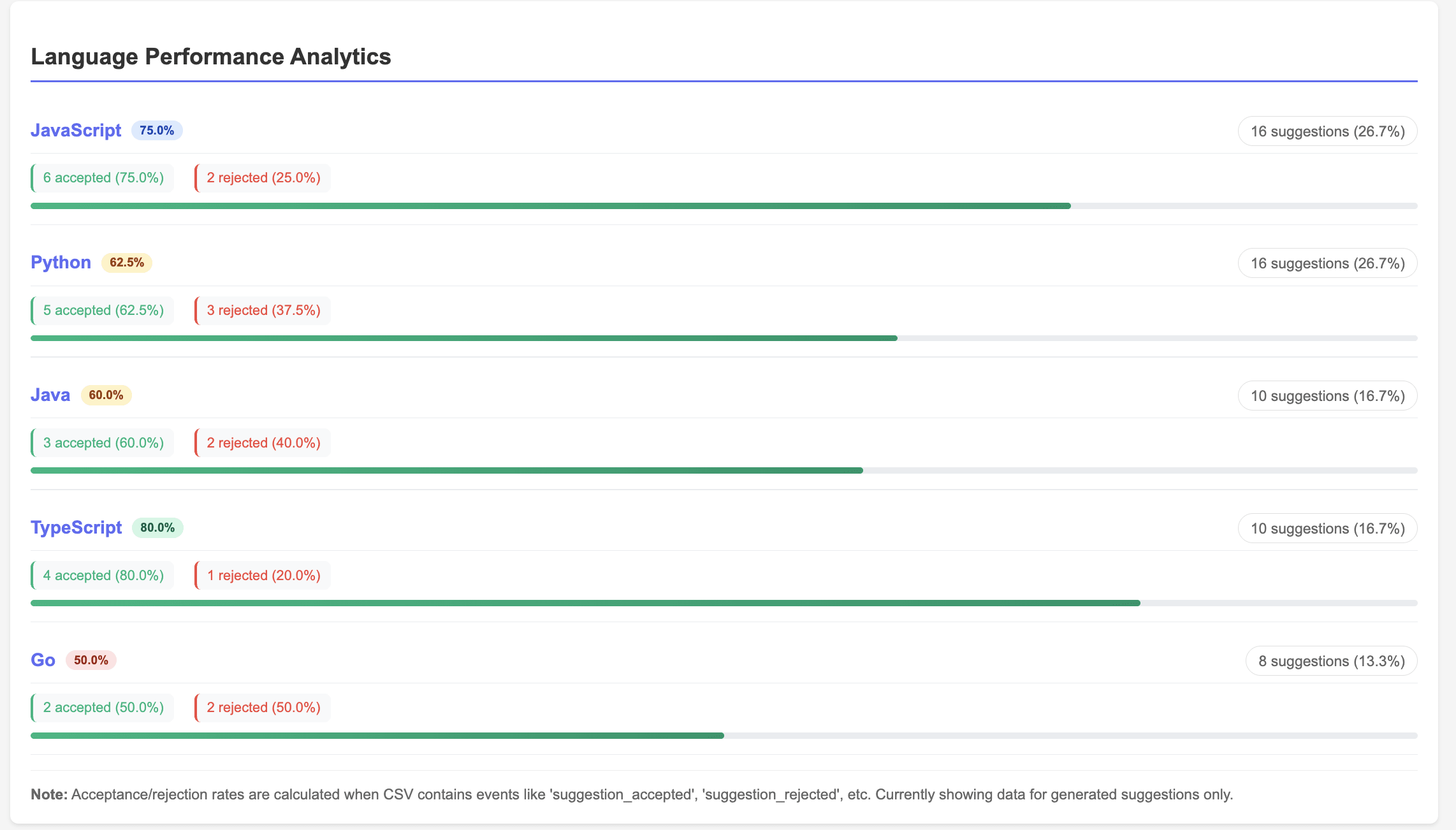
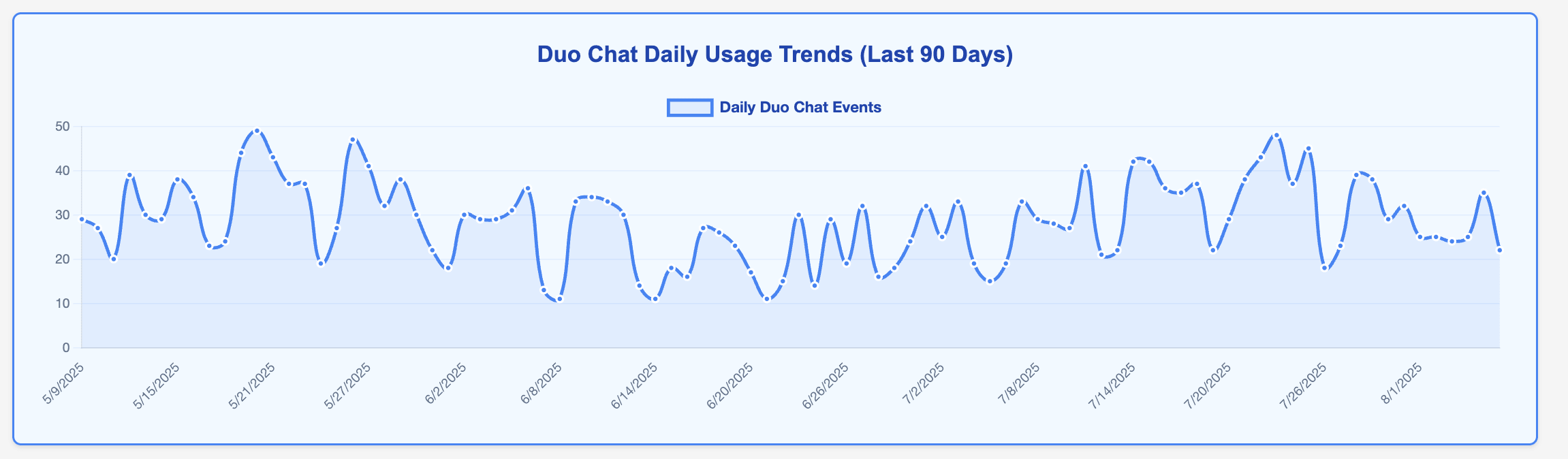

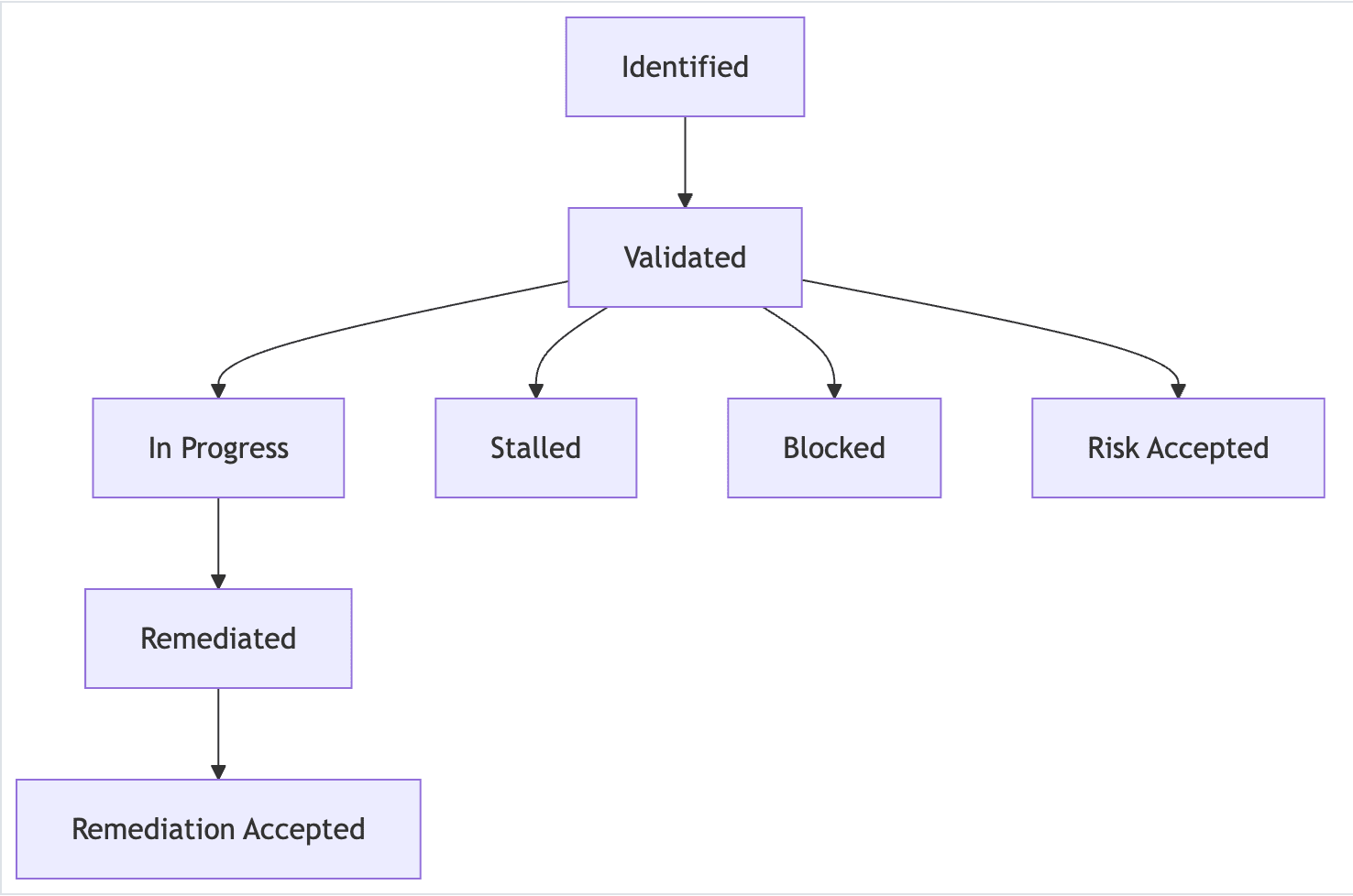 <center><i>Example of observation lifecycle</i></center>
<center><i>Example of observation lifecycle</i></center>

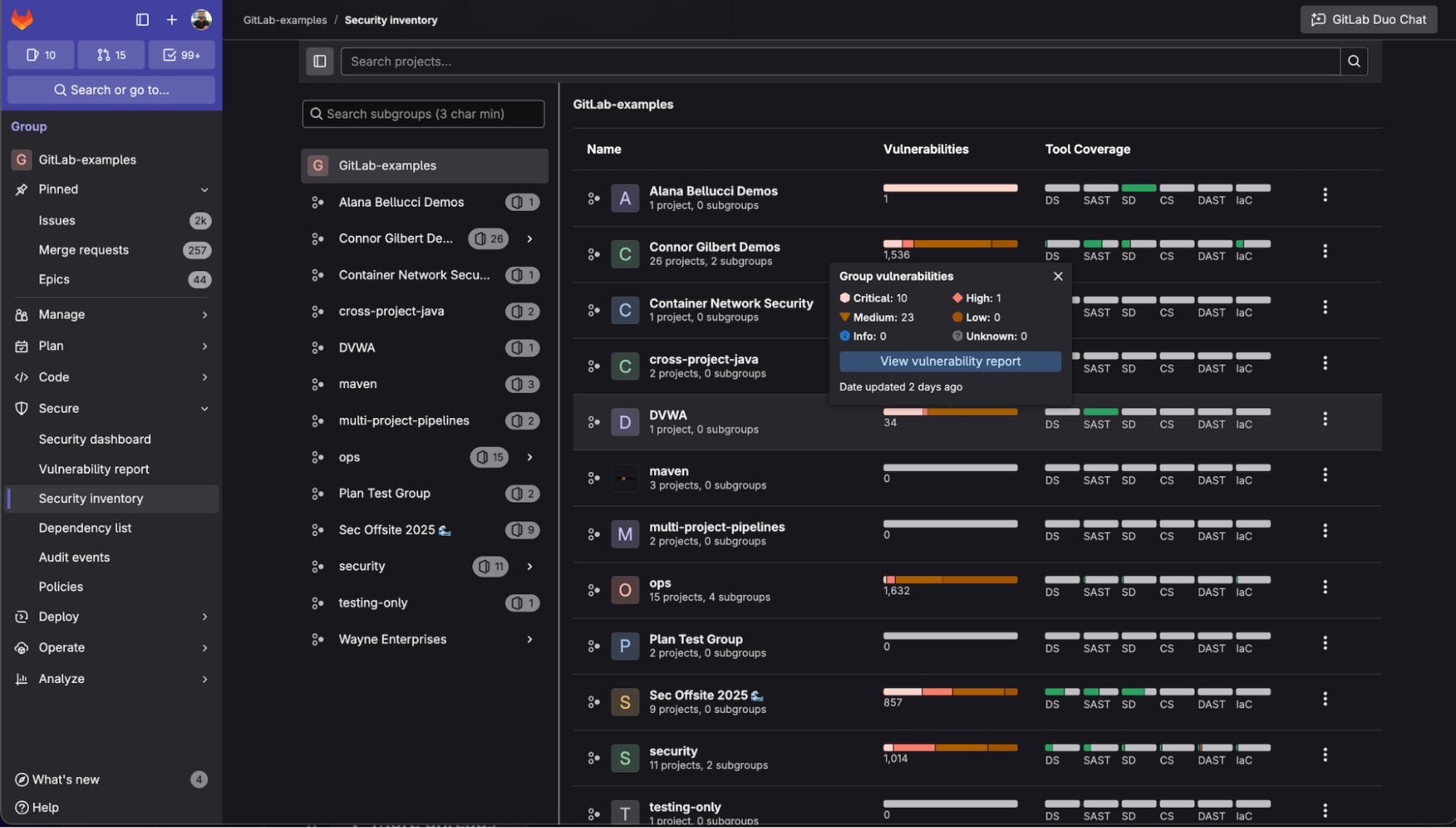 Learn more by watching Security Inventory in action:
<!-- blank line --> <figure class="video_container"> <iframe src="https://www.youtube.com/embed/yqo6aJLS9Fw?si=CtYmsF-PLN1UKt83" frameborder="0" allowfullscreen="true"> </iframe> </figure> <!-- blank line -->
Learn more by watching Security Inventory in action:
<!-- blank line --> <figure class="video_container"> <iframe src="https://www.youtube.com/embed/yqo6aJLS9Fw?si=CtYmsF-PLN1UKt83" frameborder="0" allowfullscreen="true"> </iframe> </figure> <!-- blank line -->